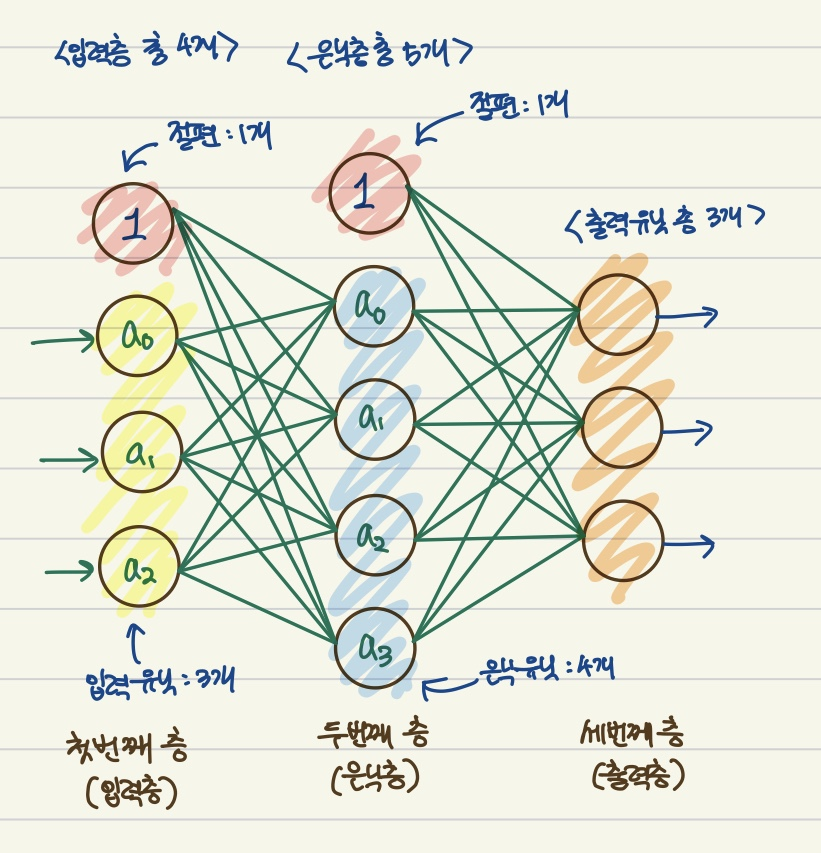
1. 주요 KMeans 파라미터:n_clusters: 클러스터의 수. 일반적으로 Elbow Method나 Silhouette Score 등을 사용하여 최적의 k 값을 찾습니다.init: 초기 클러스터 중심을 설정하는 방법. 기본값은 'k-means++'로, 클러스터 중심을 자동으로 잘 초기화합니다.'k-means++': 더 나은 초기화 방법으로, 과거의 KMeans 알고리즘보다 더 빠르고 안정적인 결과를 제공합니다.'random': 무작위로 초기 중심을 설정합니다.ndarray: 사용자 지정 중심을 제공할 수도 있습니다.max_iter: 최대 반복 횟수. 기본값은 300입니다.너무 적게 설정하면 수렴하지 않을 수 있고, 너무 크게 설정하면 계산 비용이 커질 수 있습니다.n_init: 초기화 반복 횟수. ..